D-Lib Magazine
March/April 2010
Volume 16, Number 3/4
Table of Contents
Museum Data Exchange: Learning How to Share
Günter Waibel, Ralph LeVan, Bruce Washburn
OCLC Online Computer Library Center
{waibelg, levan, bruce_washburn}@oclc.org
doi:10.1045/march2010-waibel
Printer-friendly Version
Abstract
The Museum Data Exchange, a project funded by the Andrew W. Mellon Foundation, brought together nine art museums and OCLC Research to model data sharing in the museum community. The project created tools to extract CDWA Lite XML records out of collections management systems and share them via OAI-PMH. OCLC Research harvested 900K records from participating museums and analyzed them for standards conformance and interoperability. This article describes the free or open source tools; lessons learned in harvesting museum data; findings from the data analysis; and the state of data sharing and its applications in the museum community. Museum participants were the Cleveland Museum of Art; Harvard Art Museum; Metropolitan Museum of Art; Minneapolis Institute of Arts; National Gallery of Art; National Gallery of Canada; Princeton University Art Museum; Victoria & Albert Museum and Yale University Art Gallery.
Introduction: Data sharing in fits and starts
Digital systems and the idea of aggregating museum data have a longer joint history than the availability of integrated access to museum resources in the present would suggest. As early as 1969, a newly formed consortium of 25 US art museums called the Museum Computer Network (MCN) and its commercial partner IBM declared "We must create a single information system which embraces all museum holdings in the United States" (IBM et al. 1968). In collaboration with New York University, and funded by the New York Council of the Arts and the Old Dominion Foundation, MCN created a "data bank" (Ellin 1968, 79) which eventually held cataloging information for objects from many members of the New York-centric consortium, including the Frick Collection, the Brooklyn Museum, the Solomon R. Guggenheim Museum, the Metropolitan Museum of Art, the Museum of Modern Art, the National Gallery of Art and the New York Historical Society (Parry 2007, 17).
However, using electronic systems with an eye towards data sharing was a tough sell even back in the day: when Everett Ellin, one of the chief visionaries behind the project and then Assistant Director at the Guggenheim, first shared this dream with his Director, he remembers being told: "Everett, we have more important things to do at the Guggenheim" (Kirwin 2004). The end of the tale also sounds eerily familiar to contemporary ears:
"The original grant funding for the MCN pilot project ended in 1970. Of the original fifteen partners, only the Metropolitan Museum and the Museum of Modern Art continued to catalog their collections using computerized methods and their own operating funds." (Misunas et al.)
Today, the museum community arguably is not significantly closer to a "single information system" than 40 years ago. As Nicholas Crofts aptly summarizes in the context of universal access to cultural heritage:
"We may be nearly there, but we have been "nearly there" for an awfully long time." (Crofts 2008, 2)
One of the most contemporary strategies for museum data sharing is Categories for the Description of Works of Art (CDWA) Lite XML.1 In 2005, the Getty and ARTstor created this XML schema "to describe core records for works of art and material culture" that is "intended for contribution to union catalogs and other repositories using the Open Archives Initiative (OAI) harvesting protocol".2 Arguably, this is the most comprehensive and sophisticated attempt yet to create consensus in the museum community about how to share data. The complete CDWA Lite data sharing strategy comprises:
- A data structure (CDWA) expressed in a data format (CDWA Lite XML)
- A data content standard (Cataloging Cultural Objects - CCO)
- A data transfer mechanism (Open Archives Initiative Protocol for Metadata Harvesting - OAI-PMH)
The Museum Data Exchange (MDE) project outlined in this paper attempts to lower the barrier for adoption of this data sharing strategy by providing free tools to create and share CDWA Lite XML descriptions, and helped model data exchange with nine participating museums. The activities were generously funded by the Andrew W. Mellon Foundation, and supported by OCLC Research in collaboration with museum participants from the RLG Partnership. The project's premise: while technological hurdles are by no means the only obstacle in the way of more ubiquitous data sharing, having a no-cost infrastructure to create standards-based descriptions should free institutions to debate the thorny policy questions which ultimately underlie a 40 year history of fits and starts in museum data sharing.
Grant overview
The grant proposal funded by the Andrew W. Mellon Foundation in December 2007 with $145,0003 contained the following consecutive phases:
Phase 1: Creation of a batch export capability
The grant proposed to make a collaborative investment into a shared solution for generating CDWA Lite XML, rather than many isolated local investments with little community-wide impact. We concentrated our investigation for an export mechanism on Gallery Systems' TMS, the collections management system used by participants in this phase of the grant.
Museum partners: Harvard Art Museum (originally Museum of Fine Arts, Boston; the grant migrated with staff from the MFA to Harvard early in the project); Metropolitan Museum of Art; National Gallery of Art; Princeton University Art Museum; Yale University Art Gallery.
Phase 2: Model data exchange processes through the creation of a research aggregation
The grant proposed to model data exchange processes among museum participants in a low-stakes environment by creating a non-public aggregation with data contributions utilizing the tools created in Phase 1, plus additional participants using alternative mechanisms. The grant purposefully limited data sharing to records only — including digital images would have put an additional strain on the harvesting process, and added little value to the predominant use of the aggregation for data analysis (see Phase 3).
Museum partners: all named in Phase 1, plus the Cleveland Museum of Art and the Victoria & Albert Museum (both contributing through a pre-existing export mechanism); in the process of the grant, data sets from the Minneapolis Institute of Arts and the National Gallery of Canada were also added.
Phase 3: Analysis of the research aggregation
Since the CDWA Lite / OAI strategy had been expressly created to support large-scale aggregation, the grant proposed to surface the characteristics of the research aggregation, both its potential utility and limitations, through a data analysis performed by OCLC Research.
Museum partners: all nine institutions named under Phase 1 and Phase 2.
A more detailed report on the grant, including the names of individuals who participated in the activities outlined above, can be found at http://www.oclc.org/research/publications/library/2010/2010-02.pdf.
Phase 1: Creating tools for data sharing
The suite of tools which emerged as part of the MDE project includes COBOAT and OAICatMuseum 1.0.
COBOAT is a metadata publishing tool developed by Cogapp (a digital media company headquartered in the UK) as a by-product of many museum contracts which required accessing and processing data from collections management systems. It transfers information between databases (such as collections management systems) and different formats. As part of this project, Cogapp created an open-source plug-in module which trained the tool to convert data into CDWA Lite XML. COBOAT software (as well as in-depth documentation) is available under a fee-free license for the purposes of publishing a CDWA Lite repository of collections information at http://www.oclc.org/research/activities/coboat/.
While the MDE project created and implemented COBOAT configuration files for Gallery Systems TMS, the tool can be extended to other database systems. With the appropriately tailored configuration files, COBOAT can retrieve data from Oracle, MySQL, Microsoft Access, FileMaker, Valentina or PostgreSQL databases, as well as any ODBC data source (such as Microsoft SQL Server). Gallery Systems has tested the flexibility of COBOAT by creating configuration files for its EmbARK product, which is based on the 4th Dimension database system and has a different data structure from TMS. The EmbARK configuration files can be found at http://sites.google.com/site/museumdataexchange/, a website for sharing and discussing COBOAT extensions.
The following diagram provides an overview of the modules contained in COBOAT, and the configuration files which instruct different processes.
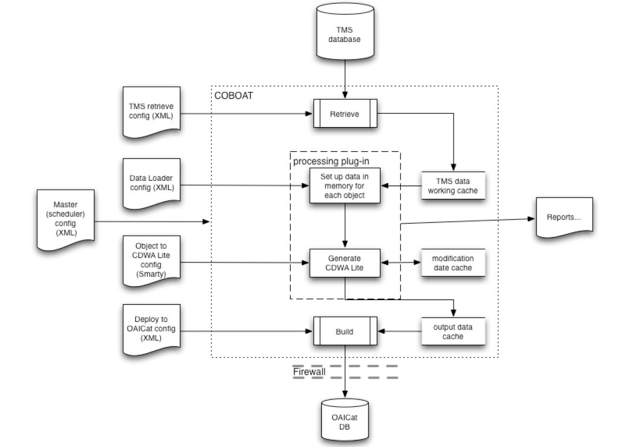
Figure 1: Block diagram of COBOAT, its modules and configuration files.
COBOAT consists of a total of five modules. Each of these modules can be customized through configuration files or scripts. Primary to extracting and transforming data to CDWA Lite XML, as well as adapting COBOAT to different databases or database instances, are the following three modules:
- Retrieve module: extracts data out of a database (by default, TMS). The retrieve configuration file (XML) determines which data to grab, and creates a series of text files from the database tables.
- Processing module or plug-in: performs transformation to CDWA Lite XML. Two configuration files are used for this procedure: the 1st pass data loader script (XML) assembles data arrays, while the 2nd pass renderer script (Smarty4) turns the data arrays into CDWA Lite XML.
- Build module: the build script (XML) outputs the data to a simple MySQL database (used by OAICatMuseum)
OAICatMuseum 1.0 is an OAI-PMH data content provider supporting CDWA Lite XML which allows museums to publish the data extracted with COBOAT. While COBOAT and OAICatMuseum can be used separately, they do make a handsome pair: COBOAT creates a MySQL database containing the CDWA Lite XML records, which OAICatMuseum makes available to harvesters. OAICatMuseum is based on OAICat and OAICatMuseumBETA (both created by Jeff Young, OCLC Research), and was created by Bruce Washburn in consultation with Jeff Young. OAICatMuseum 1.0 is available under an open source license at http://www.oclc.org/research/activities/oaicatmuseum/.
COBOAT keeps track of changes to the data source, and outputs updated modification dates for edited records to OAICatMuseum. (In this way, the suite of tools allows a data harvester to request only records which have been updated, instead of re-harvesting a complete set.) Based on an "OAISet" marker in TMS object packages, COBOAT also generates data about OAI sets. (This allows a museum to expose differently scoped sets of data for harvesting.) Beyond CDWA Lite, OAICatMuseum also offers Dublin Core for harvesting, as mandated by the OAI-PMH specification. The application creates Dublin Core from the CDWA Lite source data on the fly via a stylesheet.
Phase 2: Creating a research aggregation
Legal agreements
A legal agreement governed the data transfers between museum participants and OCLC Research. In the spirit of creating a safe sand-box environment for experimenting with the technological aspects of data sharing, the one and a half page agreement aimed to clarify that access to all data would remain limited to the participating museums; that the data would be purged one year after publication of the project report; that OCLC Research data analysis findings (part of this report) dealing with museum data would be anonymized; and that legitimate third party researchers could petition for access to the aggregation under identical terms to augment the communities knowledge of aggregate museum data. More information on third party analysis is available at http://www.oclc.org/research/activities/museumdata/default.htm.
Harvesting records
Not every participant in the grant used COBOAT and OAICatMuseum to encode and transfer their data. For the research aggregation and data analysis portion of the project, three institutions used alternative means to create and share CDWA Lite records.
- The Cleveland Museum of Art used a pre-existing mechanism for creating CDWA Lite records on the fly from their web online collection database in response to OAI-PMH requests. (Incidentally, this mechanism was built by Cogapp.)
- The Victoria & Albert Museum transformed an XML export from their MUSIMS (SSL) collections management system into CDWA Lite using stylesheets, and FTPed the data.
- The National Gallery of Canada, like the Minneapolis Institute of Arts, joined the project as a non-funded partner once shared interests emerged. The Gallery's vendor, Selago Design, crucially enabled their participation by prototyping a CDWA Lite / OAI capacity in their MIMSY XG5 collections management system, for which the MDE harvest constituted the first test.
Of all nine institutions whose records the project acquired, OAI-PMH was the transfer mechanism of choice in six cases, with four institutions using OAICatMuseum, and two an alternate OAI data content provider (Cleveland and the National Gallery of Canada). Two additional institutions wanted to employ OAICatMuseum, yet found their attempts thwarted. Policy reasons disallowed opening a port for the harvest at one museum; at another institution, project participants and OCLC Research ran out of time diagnosing a technical issue, and the museum contributed MySQL dump files from the COBOAT-created database instead. And last but not least, the Victoria & Albert Museum simply FTPed their records.
Once a set of institutional records was acquired, OCLC Research performed an initial XML schema validation as a first health-check for the data. For two data contributors, all records validated. Among the other contributors, the health-check surfaced a range of minor validation issues. The two validating record sets came from institutions using COBOAT who had not tweaked the default configuration files. Many of the element sequencing, incorrect path and missing namespace issues were introduced in those portions of the output which had been edited.
Two lessons from harvesting the nine collections stand out: first, OAI-PMH as a tool is ill-matched to the task of large one-time data transfers, compared to an FTP or rsync transfer of records, or an e-mail of mySQL dumps. Data providers reap the benefit of the protocol predominantly through its long-term use, when additions and updates to a data set can be effectively and automatically communicated to harvesters. Within the confines of the MDE project, however, OAI remained the preferred mode of data transfer, since the grant set an explicit goal of taking institutions through an OAI process. Second, the relatively high rate of schema validation errors after harvest leads to the conclusion that validation was not part of the process on the contributor end. Ideally, schema validation would have happened before data contribution. Validation provides the contributor with important evidence about potential mapping problems, as well as other issues in the data; in this way, it becomes one of the safeguards for circulating records which best reflect the museums data.
Preparing for data analysis
To prepare the harvested data for analysis, as well as to provide access to the museum data, OCLC Research harnessed the Pears database engine,6 which Ralph LeVan (OCLC Research) outfitted with new reporting capabilities, and an array of pre-existing and custom-written tools. Pears ingests structured data, in this case XML, and creates a list of all data elements or attributes (referred to as "units of information" from here on out) which contain a data value. The database then builds indexes for the data values of each of these units of information. The values themselves remain unchanged, except that they are shifted to lower case during index building. For data analysis, these indexes provide a basis for grouping values from a specific unit of information for a single contributor, or the aggregate collection; as well as grouping the units of information themselves via tagpaths across the array of contributors.
The following screen-shots of sample reports from Pears, here shown in spreadsheet format, should help bring these abstract concepts to life.
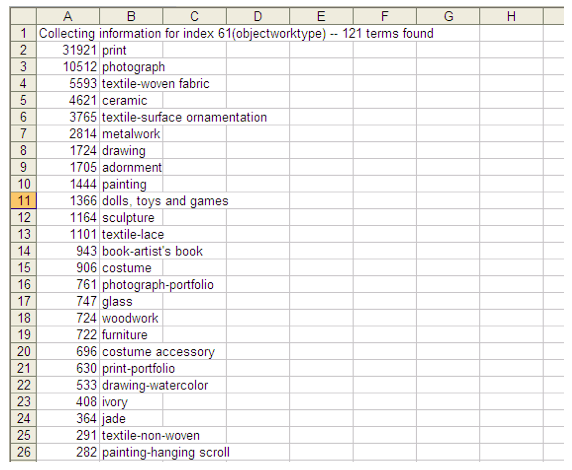
Figure 2: Excerpt from a report detailing all data values for objectWorkType from a single contributor.
In Figure 2, column A provides counts for the number of occurrences for each data value. (Note that only 26 of the 121 values for objectWorkType are shown.) Just at a simple intuitive level, this report provides some valuable information: first of all, it demonstrates that objectWorkTypes for this contributor were limited to a finite number of 121; it shows that a number of terms were concatenated, probably in the process of exporting the data, to create values such as "drawing-watercolor"; at first glance, only these concatenated values seem to duplicate other entries (such as "drawing"). The occurrence data indicates a high concentration of objects sharing the same objectWorkType, with numbers quickly falling below a 1K count.
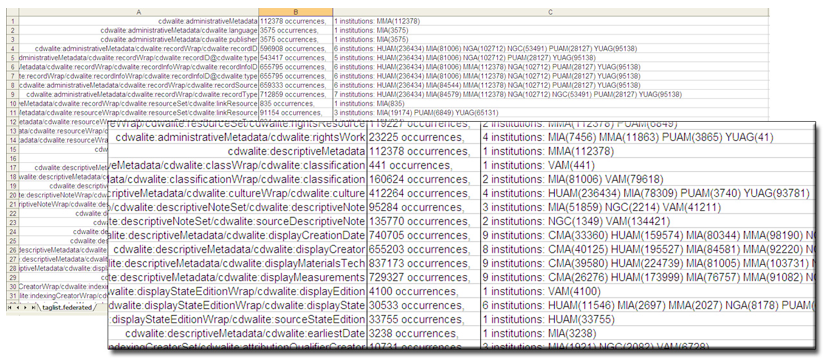
Figure 3: Excerpt of a report detailing all of units of the information containing a data value across the research aggregation.
Figure 3 shows an excerpt of a report which groups units of information from all contributors. Even in the impressionistic form of a screenshot, this report provides some valuable first impressions of the data. Data paths (column A) which have long lists of institutions associated with them (column C) represent units of information which are used by many contributors; occurrence counts in column B, when mentally held against the approximately 900K total records of the research aggregation, complement the first observation by providing a first impression of the pervasiveness with which certain units of information are used. Outlier data paths which have only a single institution associated with them often betray an incorrect path, as confirmed by schema validation results. While OCLC Research held fast to a principle of not manipulating the source data provided by museums, the single instance of data clean-up performed prior to analysis consisted in mapping stray data paths to their correct place.
Exposing the research aggregation to participants
Figure 4: Screenshot of the no-frills search interface to the MDE research aggregation.
In addition to supporting data prep for analysis, Pears also provided a low-overhead mechanism for making individual databases as well as the research aggregation of all nine contributors available to project participants. By simply adding a stylesheet, the SRW/U (Search/Retrieve via the Web or URL) enabled Pears to turn into a database with searchable or browseable indexes. Project participants had password-protected access to both the aggregate as well as the individual datasets.
Phase 3: Analysis of the research aggregation
Before OCLC Research started the data analysis process, museum participants formulated the questions which they would like to ask of their institutional and collective data. These questions were formalized and expanded upon in a methodology7 to guide the overall analysis efforts. This methodology grouped questions into two sections — a Metrics sections which contained questions with objective, factual answers, and an Evaluation section which contained questions that are by their nature more subjective. The Metrics section asks questions about Conformance (does the data conform to what the applicable standards — CDWA Lite and CCO - stipulate?), as well as Connections (what overt relationships between records does the data support?). Connections questions in essence try to triangulate the elusive question of interoperability. The section on Evaluation asks questions about Suitability (how well do the records support search, retrieval, aggregation?), as well as Enhancement (how can the suitability for search, retrieval, aggregation can be improved?).
The methodology was not intended to be a definitive checklist of all questions the project intended to plumb. It laid out the realm of possibilities, and allowed OCLC Research to discuss which questions it could tackle given expertise, available tools and time constraints. OCLC Research itself predominantly worked on questions regarding CDWA Lite conformance, while an analysis of CCO compliance was outsourced to Patricia Harpring and Antonio Beecroft (Harpring 2009). Most questions pertaining to Evaluation, however, were beyond the reach of our project.
Getting familiar with the data
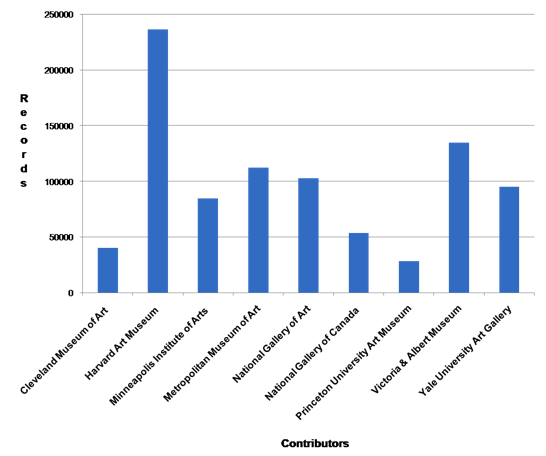
Figure 5: Records contributed by MDE participants.
Overall, a total of 887,572 records were contributed by nine museums in Phase 2 of the grant. Six out of nine museums contributed all accessioned objects in their database at the time of harvest. Of the remaining three, one chose a subset of all materials published on their website, while two made decisions based on the perceived state of cataloging. Among those providing subsets of data, the approximate percentages range from one third to a little over 50% of the data in their collections management system.
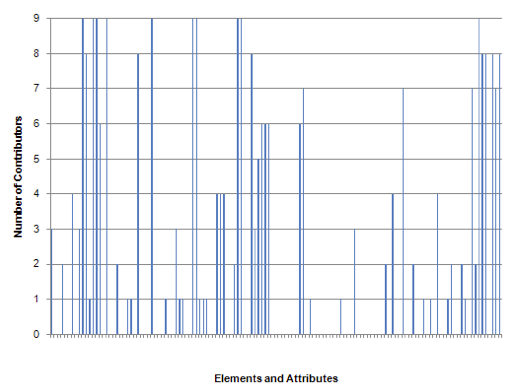
Figure 6: Use of possible CDWA Lite elements and attributes across contributing institutions, take 1.
Figure 6 shows the distribution of element/attribute use across the aggregation: the graph shows the number of contributors that had made any use the possible 131 CDWA Lite units of information.8 A relatively small number (10 out of 131, or 7.6%) of elements/attributes are used at least once by all nine museums. These units of information are:
- displayCreationDate (CDWA Lite Required)
- displayMaterialsTech (CDWA Lite Required)
- displayMeasurements (CDWA Lite Highly Recommended)
- earliestDate (CDWA Lite Required)
- latestDate (CDWA Lite Required)
- locationName (CDWA Lite Required)
- "type" attribute on locationName (Attribute)
- nameCreator (CDWA Lite Required)
- nationalityCreator (CDWA Lite Highly Recommended)
- title (CDWA Lite Required)
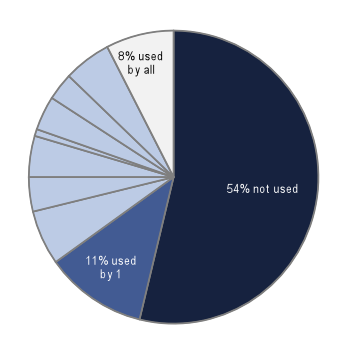
Figure 7: Use of possible CDWA Lite elements and attributes across contributing institutions, take 2.
A final look at the distribution of use for the totality of all CDWA Lite elements/attributes makes it easy to see how many units of information are not used at all (approximately 54%) and how many are used at least once by all contributors (approximately 8%).
Conformance to CDWA Lite, part 1: Cardinality
The CDWA Lite specification calls 12 data elements "required", and 5 elements "highly recommended". In theory, the required elements are mandatory for schema validation9 — in practice, the vast majority of records which did not contain a data value in a required element still passed the schema validation test, since declaring the data element itself suffices for validation.
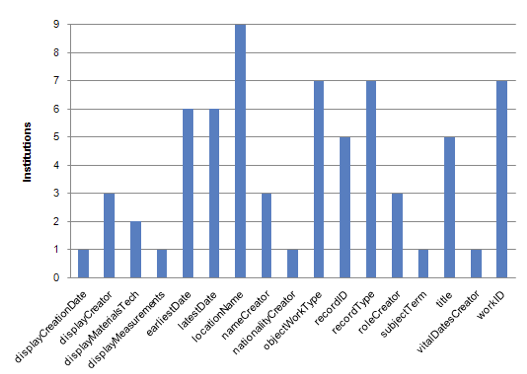
Figure 8: Consistent use of CDWA Lite required / highly recommended elements.
A graph of the institutions which provided values for CDWA Lite required / highly recommended elements for all of their records shows how comprehensive these elements were utilized. locationName emerges as the only element consistently present in all records across all nine contributors. Almost 50% (8 of the 17) required / highly recommended elements occur consistently in 5 or more contributors. A little over 50% (9 of the 17) required / highly recommended elements occur consistently in only 3 or less museum contributors.
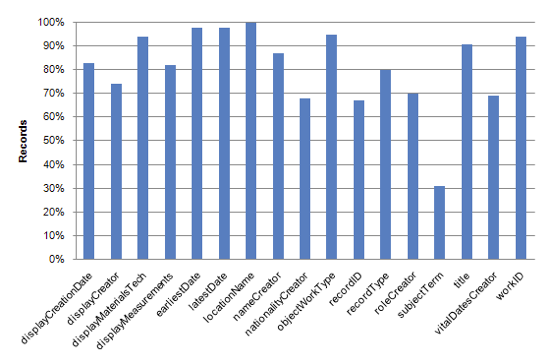
Figure 9: Use of CDWA Lite required / highly recommended elements by percentage.
Figure 9 shows the percentage of records in the research aggregation that have values in the required / highly recommended elements (Figure 9). Discounting the outlier subjectTerm, the consistency with which these elements occur is greater than 65% overall. For 7 of 17 elements, consistency is above 90%.
Excursion: the default COBOAT Mapping
At this point, a short break from figures and a disclaimer about the data is in order. Project participants submitted data to the research aggregation as part of an abstract exercise. The project parameters made no demand of them other than to make CDWA Lite records available. Consequently, fields which may very well be present in source systems remained unpopulated in the submitted CDWA Lite records. At the point where OCLC Research accepted the data contribution because of the time constraints of the grant project, a real life aggregator may have gone back to negotiate for further data values deemed crucial to a specific service.
For the 6 of 9 contributors using COBOAT, the default mapping provided with the application heavily influenced their data contribution. The default COBOAT mapping uses 32 units of information of the 131 defined in the CDWA Lite schema. All CDWA Lite required/recommended elements and attributes are in the default mapping, except for subjectTerm. (subjectTerm did not appear in any of the mapping documents museums submitted as part of the project.)10 COBOAT participants did have the option of adding further data elements and attributes, which contributors made limited use of: 4 out of 6 COBOAT contributors used, in various combinations, 11 additional elements and attributes.
Conformance to CDWA Lite, part 2: Controlled vocabularies
CDWA Lite, as well as its attendant data content standard CCO, recommends the use of controlled vocabularies for 13 data elements, six of which are required / highly recommended:
- objectWorkType
- nameCreator
- nationalityCreator
- roleCreator
- locationName
- subjectTerm
None of the contributing museums had marked the use of controlled vocabularies on any of the six elements in question. (The "termSource" attribute was not part of the COBOAT default export). To get a sense of the deliberate or incidental use of values from controlled vocabularies, OCLC Research created a list of the top 100 most frequently used terms for each participating museum, de-duplicated the lists (sometimes identical terms were frequently used at multiple museums), and then matched the remaining terms to a controlled vocabulary source recommended by CDWA Lite, i.e., vocabularies published by the Getty. For subjectTerm, nationalityCreator and locationName, the results of data matching were questionable: for subjectTerm, the source data did not constitute a compelling sample; for nationalityCreator and locationName, concatenated values prohibited matches, while at the same time, many source values found multiple matches in the Getty Thesaurus of Geographic Names®. Reasonably indicative, however, are the matches of nameCreator in ULAN, objectWorkType in AAT, roleCreator in AAT.
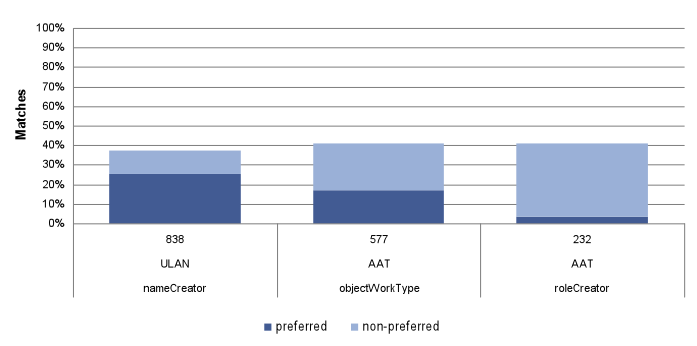
Figure 10: Match rate of required / highly recommended elements to applicable controlled vocabularies.
ULAN = Union List of Artist Names®;
AAT = Art & Architecture Thesaurus®
The data matching exploration highlights whether connections with an applicable thesaurus are possible without expertise-intensive and costly processing of data. Matches shown in Figure 10 are exact matches achieved without any manipulation of the source data. (The numbers along the x-axis, above the vocabulary acronym, give the total count of the top 100 values. For example, objectWorkType is represented by 577 top 100 de-duplicated values from the 8 institutions which contributed values for this element.) In some instances, higher match rates might have been achieved by post-processing, for example by splitting concatenated data values museums had contributed. Some values matched on multiple entries in their corresponding controlled vocabulary (more details below). Figure 10 includes the multi-matching values in the percentage counts.
nameCreator and ULAN
All nine institutions contributed nameCreator data values. The count for de-duplicated top 100 nameCreators is 838 across the nine contributing institutions. 37% of nameCreators (314 of the 838) match on a ULAN term, with 213 matching on a preferred term, and 101 matching on a non-preferred term. 1% of these 37% represent terms which match on more than one ULAN term.
objectWorkType and AAT
Eight out of nine institutions contributed objectWorkType data values. The count for de-duplicated top 100 objectWorkTypes is 577 across the eight contributing institutions. (As would be expected, for some institutions, the sum total of all their objectWorkTypes is less than 100). 41% of objectWorkTypes (236 out of 577) match on an AAT term, with 98 matching on a preferred term, and 138 matching on a non-preferred term. 8% of these 41% represent terms which match on more than one AAT term.
roleCreator and AAT
Seven out of nine institutions contributed roleCreator data values. The count for de-duplicated top 100 roleCreators is 232 across the seven contributing institutions. (As would be expected, for most institutions, the sum total of all their roleCreators is less than 100). 41% of roleCreators (95 of the 232) match on an AAT term, with nine matching on a preferred term, and 86 matching on a non-preferred term. 7% of these 41% represent terms which match on more than one AAT term.
In summary, the vocabulary matching exercise indicates that in order to preserve the possibility of extending museum data with the rich information available in thesauri, even knowing the source thesaurus would have been only marginally helpful. Performing some data processing on the museum data could have created higher match rates. However, the value of using controlled vocabularies for search optimization or data enrichment can only be fully realized if the termsourceID is captured alongside termSource to establish a firm lock on the appropriate vocabulary term.
Economically adding value: controlling more terms
The high record count with which many individual data values on the top 100 lists are associated suggests opportunities for adding value to the data by controlling a relatively low number of terms with impact on a relatively high number of records per data set.
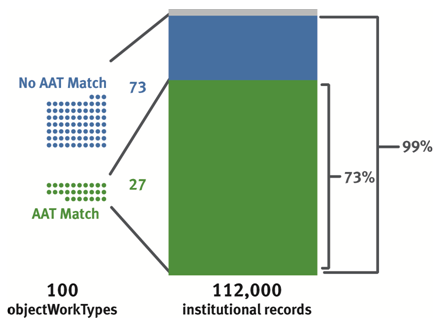
Figure 11: Top 100 objectWorkTypes and their corresponding records for the Metropolitan Museum of Art.
Consider the example for objectWorkType values in records from the Metropolitan Museum of Art depicted in Figure 11:
- The top 100 objectWorkTypes represent 99% of objectWorkType values in all 112,000 Metropolitan records.
- The top 100 objectWorkTypes matching on either a preferred or a non-preferred AAT term represent 27 matches, which is equal to 73% of all Metropolitan records. (8 of these 27 matches contain terms which match on more than one AAT entry.)
- The top 100 objectWorkTypes not matching on any AAT term represent 73, which is equal to 26% of all Metropolitan records.
In other words, by tending to 73 objectWorkType values and disambiguating an additional 8, the Metropolitan could extend objectWorkType control to 99% of all 112,000 Metropolitan Museum records.
Across the entire aggregation, by tending to 341 objectWorkTypes and disambiguating an additional 46, the aggregate collection control for objectWorkType could be extended to 94% of all 847,000 records.
A data element like objectWorkType would be expected to produce favorable numbers in this type of analysis: by its very nature, objectWorkType contains a relatively low number of values which presumably reappear across many records in a collection. For nameCreator, a data element which has a relatively high number of values across aggregation records, one would expect a less impressive result from focusing on top 100 terms.
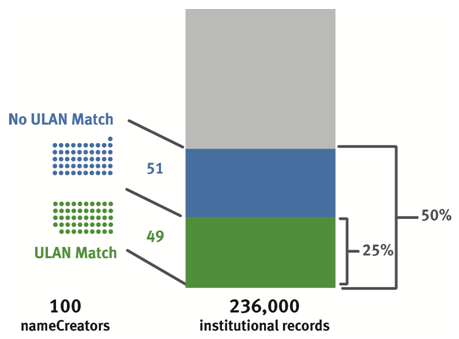
Figure 12: Top 100 nameCreators and their corresponding records for the Harvard Art Museum.
However, consider the example depicted in Figure 12 from the Harvard Art Museum:
- The top 100 nameCreators represent 50% of nameCreators in all 236,000 Harvard records.
- The top 100 nameCreators matching on either a preferred or a non-preferred ULAN term represent 49 matches, which represent 25% of all Harvard records. (2 of the top 49 matches contain terms which match on more than one ULAN entry).
- The top 100 nameCreators not matching on any ULAN term represent 51, which represent 26% of all Harvard records.
In other words, by tending to 51 nameCreator values and disambiguating an additional 2, Harvard could extend nameCreator control to 50% of all 236,000 Harvard records. While the overall percentages for nameCreator are necessarily lower than for objectWorkType, doubling the rate of control still constitutes a formidable result.
Across the entire aggregation, by tending to 524 nameCreators and disambiguating an additional 8, the aggregate collection control for nameCreator could be extended to 49% of all 888,000 aggregation records.
Connections: Data values used across the aggregation
Apart from evaluating conformance to CDWA Lite and vocabulary use, OCLC Research at least dipped its toe into the murky waters of testing for interoperability. By asking questions about how consistently data values appeared across the nine contributors to the aggregation, some first impressions of cohesion can be triangulated. This investigation concentrated on a select number of data elements which are required / highly recommended by CDWA Lite, widely used by contributors and presumably of prominent use for searching and browse lists. For these elements, the top 100 values for each museum were cross-checked against other contributors to establish how many institutions use that same value, and with what frequency (i.e. in how many records.)
The following tables provide a small sample from the resulting spreadsheets:
| nameCreator |
objectWorkType |
| Value |
Contributors |
Records |
|
Value |
Contributors |
Records |
| parmigianino |
8 |
783 |
|
sculpture |
8 |
10369 |
| raphael |
8 |
1127 |
|
print |
6 |
175588 |
| abbott, berenice |
6 |
572 |
|
photograph |
6 |
86017 |
| albers, josef |
6 |
564 |
|
drawing |
6 |
58140 |
| beuys, joseph |
6 |
975 |
|
painting |
6 |
15837 |
| blake, william |
6 |
1054 |
|
furniture |
6 |
2206 |
| bonnard, pierre |
6 |
623 |
|
book |
5 |
15644 |
| bourne, samuel |
6 |
806 |
|
paintings |
5 |
9612 |
| brandt, bill |
6 |
611 |
|
ceramic |
5 |
5562 |
| chagall, marc |
6 |
2207 |
|
textiles |
5 |
3898 |
| |
textile |
5 |
1775 |
| nationalityCreator |
portfolio |
5 |
861 |
| Value |
Contributors |
Records |
|
calligraphy |
5 |
822 |
| american |
9 |
248206 |
|
glass |
5 |
800 |
| australian |
9 |
1578 |
|
manuscript |
5 |
534 |
| austrian |
9 |
2443 |
|
poster |
4 |
3493 |
| belgian |
9 |
1057 |
|
metalwork |
4 |
2826 |
| brazilian |
9 |
221 |
|
plate |
4 |
1851 |
| british |
9 |
50924 |
|
costume |
4 |
956 |
| canadian |
9 |
15776 |
|
album |
4 |
823 |
| chinese |
9 |
2905 |
|
wallpaper |
4 |
500 |
| cuban |
9 |
188 |
|
sketchbook |
4 |
356 |
| danish |
9 |
591 |
|
frame |
4 |
297 |
| |
collage |
4 |
132 |
| roleCreator |
mosaic |
4 |
116 |
| Value |
Contributors |
Records |
|
prints |
3 |
8814 |
| artist |
6 |
475747 |
|
negative |
3 |
7235 |
| engraver |
6 |
6465 |
|
photographs |
3 |
7081 |
| printer |
6 |
14009 |
|
jewelry |
3 |
3662 |
| publisher |
6 |
25535 |
|
vase |
3 |
2663 |
| designer |
5 |
19130 |
|
dish |
3 |
2440 |
| editor |
5 |
1704 |
|
bowl |
3 |
2328 |
| etcher |
5 |
1822 |
|
tile |
3 |
1707 |
| lithographer |
5 |
1496 |
|
ring |
3 |
1279 |
| painter |
5 |
1376 |
|
medal |
3 |
1277 |
| architect |
4 |
667 |
|
jug |
3 |
1271 |
Figure 13: Most widely shared values across the aggregation for nameCreator, nationalityCreator, roleCreator and objectWorkType.
With a small amount of additional processing, the spreadsheets underlying these figures allow statements about how many values in a specific data element are shared across how many institutions, and how many records these elements represent. Figure 14 and Figure 15 explore what can be learned about the Aggregates cohesiveness by looking at nationalityCreator and objectWorkType.
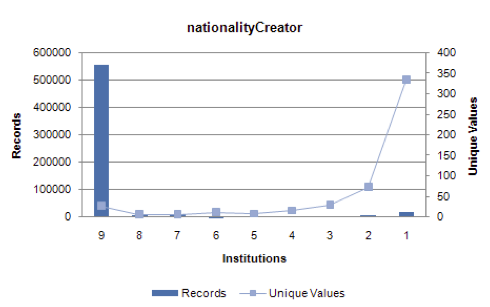
Figure 14: nationalityCreator: relating records, institutions, and unique values.
For nationalityCreator, the distribution of unique values and associated records across the nine participating institutions matches what one would expect from browsing the data, given the preponderance of nationalityCreator values from a small set of countries. A relatively small number of unique values (28) are present in the data from all nine participants, and correlate to a large number of records (554K). Additionally, one would expect to see many unique values represented in the data shared by one or two institutions, with correspondingly low numbers of associated records, for those nationalities that are less common. Sure enough, 408 nationalityCreator values are held by any two or a single institution, representing 26K records, or 2.9% of the entire aggregate. Given this appraisal, nationalityCreator values seem to form a coherent set of data values.
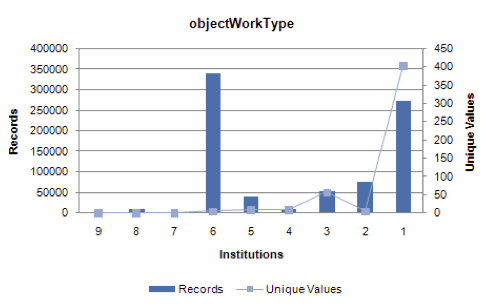
Figure 15: nationalityCreator: relating records, institutions, and unique values.
For objectWorkType, the distribution of unique values and associated records across the nine participating institutions show a less coherent mix. (In part, this can be attributed to small differences in values preventing a match, such as the singular and plural forms for a term evident for objectWorkType in Figure 13: print(s), photograph(s), painting(s), textile(s), etc.) Since only eight institutions contributed objectWorkType data, no unique objectWorkType values are represented across all contributors. Only one value is found in the data of eight contributors. The first spike in the graph occurs at five values found in the data of six museums. Though those five values account for a significant number of records (338K, or 38% of the Aggregate), one would have expected the number for both widely shared values and corresponding record counts to be higher. Moving on to the spike at values present in a single museum's data, it is hard to conceive that the high number of unique values (404) representing a high number of records (273K, or 30% of the Aggregate) accurately reflects the underlying collections. The large number of unique objectWorkTypes suggests an opportunity to reduce noise in the data via more rigorous application of controlled vocabulary (according to Figure 10, the current match rate to AAT is 41%), which would produce a set of unique values that could be more sensible to browse.
A note about record identifiers
Persistent and unique record identifiers are essential for supporting linking and retrieval, as well as data management of records across systems. Without a reliable identifier it is difficult or impossible to match incoming records for adds, updates, and deletes, or to link to a specific record. In other words, a reliable identifier unlocks one of the chief benefits of using OAI-PMH for data sharing, the ability to keep a data contribution to a third party current with changes in the local museum system. There are four places in the OAI-PMH and CDWA Lite data where unique record identifiers may be supplied:
- recordID: CDWA Lite Required, CCO Required
"A unique record identification in the contributor's (local) system"11
- recordInfoID: Not required or recommended
"Unique ID of the metadata. Record Info ID has the same definition as Record ID but out of the context of original local system, such as a persistent identifier or an oai identifier"
- workID: CDWA Lite Highly Recommended, CCO Required
"Any unique numeric or alphanumeric identifier(s) assigned to a work by a repository"
- OAI-PMH Identifier
OAI Required. Schema, repository, and item id. E.g., oai:artsmia.org:10507
Among the data contributors, 6 of 9 used recordID and recordInfoID, 8 of 9 used workID, some used both. (Both were defined in the default COBOAT mapping.) All contributors used at least one of the CDWA Lite identifiers.

Figure 16: Screenshot of a search result from the research aggregation.
When identifiers are supplied that are not unique across an aggregation, disambiguation problems develop. As depicted in Figure 16, the identifier "1953.155" is used by two different contributors for two different works.
From a data aggregator's point of view, the key concern is not which data element is used to provide an identifier, but that all contributors use the same element consistently.. Given its required nature, the recordID element seems like a good candidate for consensus. Aggregators can supplement it with information about the contributor to make it unique across the collection (e.g. by using the OAI identifier or following its conventions in case not all contributors use OAI), which will help ensure efficient and reliable record processing and retrieval.
Compelling applications for data exchange capacity
The design of the MDE project allowed participants to experiment and gain experience with sharing data without necessarily having settled the policy issues with which the museum community at large is still grappling. While this approach by and large succeeded (witness the creation of tools, the sharing of data, the lessons in the data analysis), the absence of real-life requirements, a real-life audience and real-life applications for the data made it difficult for the museums to calibrate their data for submission, and for OCLC Research to evaluate it for suitability.
To survive and thrive, museum data sharing at participating institutions will need to outgrow the sandbox, become sanctioned by policies, and applied in service of goals supporting the museum mission. Needless to say, sharing data is not a goal unto itself, but an activity which needs to drive a process or application of genuine interest to an individual museum. As a natural by-product of the grant work, participants and project followers surfaced and discussed potential applications for CDWA Lite / OAI-PMH in a museum setting, and the project invited representatives from OMEKA, ARTstor, ArtsConnectEd and CHIN, as well as Gallery Systems and Selago Design, to participate in our final meeting at the Metropolitan Museum of Art on July 27th 2009. In the meantime, some of the museums have already put their new sharing infrastructure to work in production settings; others are activelyexploring their options. Below are brief sketches of the institutional goals a CDWA Lite / OAI-PMH capacity could support.
Goal: Create an exhibition website, or publish an entire collection online
OMEKA (http://omeka.org/) is a free, open source web-based publishing platform for collections created by the Center for History and New Media, George Mason University. For a museum to take advantage of this tool, a core set of data has to migrate from the local collections management system into the OMEKA platform. A museum can use COBOAT and OAICatMuseum to create an OAI data content provider, and OMEKA's OAI-PMH Harvester plug-in12 to ingest and update the data. At least one of the MDE project participants supported the test of this plug-in by providing access to their OAI-PMH installations, and others may follow.
Goal: Add a tagging feature to your online collection
Steve: The museum social tagging project (http://www.steve.museum/) is a collaboration of museum professionals exploring the benefits of social tagging for cultural collections. As part of its research, Steve has created software for a hosted tagging solution. For a museum to take advantage of this tool, its data will have to be loaded into the tagging application. The Steve tagger can harvest OAI-PMH repositories of data, and accepts data in both CDWA Lite and Dublin Core. The project team envisions that a future local version of the tagger will contain the same ingest functionality.
Goal: Disseminate authoritative descriptive records of museum objects
The Cultural Objects Name Authority (CONA™), a new Getty vocabulary of brief authoritative records for works of art and architecture, is slated to be available for contributions in 2011.13 For museums, contribution to CONA ensures that records of their works as represented in visual resources or library collections are authoritative. Although CONA is an authority, not a full-blown database of object information, it complies with the cataloging rules for adequate minimal records described in CDWA and CCO. As Patricia Harpring outlined during our final meeting, the vocabulary editorial team will accept contributions in CDWA Lite XML or in the larger CONA contribution XML format.
Goal: Expose collections for K-12 educators, students and scholars
ArtsConnectEd (http://www.artsconnected.org/) is an interactive Web site that provides access to works of art and educational resources from the Minneapolis Institute of Arts and the Walker Art Center. The Institute and the Walker pool their resources using a CDWA Lite / OAI-PMH infrastructure, and the Institute of Arts has successfully implemented the MDE tools to contribute to this aggregation (Dowden et al. 2009). At the final face-to-face MDE meeting, both ArtsConnectEd representatives and grant participants speculated about whether the resource could grow to include additional contributors. A test load of MDE dataset from the National Gallery of Canada and the Harvard Art Museum, as well as records from the Brooklyn Museum (6K) accessed via an API, illustrated the possibilities.
Goal: Expose collections to higher education
As one of the original co-creators of CDWA Lite, ARTstor (http://www.artstor.org/) welcomes contributions in CDWA Lite. During our final face-to-face project meeting, Bill Ying and Christine Kuan (both ARTstor) emphasized that ARTstor is eager to create relationships with data contributors in which repeat OAI harvesting to support updating and adding to the data becomes a matter of routine. ARTstor currently counts 80 international museums among its contributor, yet only a very small minority have contributed data via OAI. As an outcome of the MDE project, both the Harvard Art Museum and the Princeton University Art Museum are actively exploring OAI harvesting with ARTstor, while three additional participants have signaled that this would be a likely use for their OAI infrastructure as well.
Goal: Effectively expose the collective collection of a university campus (collections from libraries, archives and museums)
At Yale University, both the Yale University Art Gallery (grant participant) and the Yale Center for British Art (an avid follower of the project) are implementing COBOAT / OAICatMuseum with the goal of using this capacity for a variety of university-wide initiatives. The museums contribute data to a cross-collection search effort via OAI-PMH14 (Princeton has similar ambitions), and the Yale museums will also use the same set-up to sync data with OpenText's Artesia, a university-wide digital assets management system.15 In addition, the Art Gallery proposes to use CDWA Lite XML records to share data with the recipients of traveling collections.
Goal: Aggregate collection data for national projects
The Canadian Heritage Information Network (CHIN) is currently redeveloping Artefacts Canada (http://www.chin.gc.ca/English/Artefacts_Canada/), a resource of more than 3 million object records and 580,000 images from hundreds of museums across the country. So far, the resource grows largely via contributions of tab-delimited files and spreadsheets representing museum data, and CHIN would like to explore other mechanisms for aggregation. Corina MacDonald (CHIN), who attended the MDE final project meeting, speculated that a testbed of large Canadian institutions using COBOAT / OAICatMuseum might provide lessons for a way forward.
Conclusion: Policy challenges remain
In his insightful article "Digital Assets and Digital Burdens: Obstacles to the Dream of Universal Access", already cited in the introduction, Nicholas Crofts provides a list of false premises for data sharing:
- i. Adapting to new technology is the major obstacle to achieving universal access
- ii. The corpus of existing digital documentation is suitable for wide-scale diffusion
- iii. Memory institutions want to make their digital materials freely available (Crofts 2008, 2)
Ironically, these premises can be viewed as structuring the MDE project. The MDE grant posited that a joint investment in shareable tools (cf. i) might help force the policy question of how openly to disseminate data (cf. iii), while also allowing an investigation into how suitable museum descriptions are for aggregation (cf. ii). At the end of the day, however, there is no disagreement with Crofts' position: ultimately, policy decisions allow data sharing technology to be harnessed, or create the impetus to upgrade descriptive records.
In the case of the MDE museums, all of them had enough institutional will towards data sharing to participate in this project. As a result of this project, some have already used their new capacity for data exchange to drive mission-critical projects. A quick recap of the most significant developments catalyzed by the MDE tools: the Minneapolis Institute of Arts uses the MDE tools to contribute data to ArtsConnected; Yale University Art Museum and the Yale Center for British Art use the tools to share data with a campus-wide cross-search service, and contribute to a central digital asset management system; the Harvard Art Museum and the Princeton University Art Museum are actively exploring OAI harvesting with ARTstor, while three additional participants have signaled that this would be a likely use for their OAI infrastructure as well. Obviously, it is too early to judge the ultimate impact of making the MDE suite of tools available, yet these developments are promising.
While the data analysis efforts detailed in this paper can not be viewed as a conclusive measure for the fitness of museum descriptions, they ultimately leave a positive impression: the analysis shows good adherence to applicable standards, as well as reasonable cohesion. Where there is room for improvement, some fairly straightforward remedies can be employed. Significant improvements in the aggregation could be achieved by revisiting data mappings to allow for a more complete representation of the underlying museum data. Focusing on the top 100 most highly occurring values for key elements will impact a high number of corresponding records. Museums engaging in data exchange will learn new ways to adapt and improve their data output every time they share, and the MDE experiment was just the first step on that journey.
At the end of the day, the willingness of museums to share data more widely is tied to the compelling application for that shared data. When there are applications for sharing data which directly support the museum mission, more data is shared. When more data is shared, more such compelling applications emerge. This chicken-and-egg conundrum provides a challenge to both museum policy makers as well as those wishing to aggregate data. The list of aggregators, platforms, projects and products provided in the previous chapter which support data exchange using CDWA Lite / OAI provides hope that these compelling applications will move museum policy discussions forward.
In the summation of his paper, Nicholas Crofts lays out what is at stake:
[O]ther organisations and individuals are actively engaged in producing attractive digital content and making it widely available. Universal access to cultural heritage will likely soon become a reality, but museums may be losing their role as key players." (Crofts 2008, 13)
No matter which museum you represent, a search on Flickr® for your institution's name viscerally confirms the validity of this prediction.
It seems appropriate to close this paper with the words of a man who fought this same policy battle 40 years ago. While the 1960s were a different time indeed, the arguments sound quite familiar. In an oral history interview from 2004, here is how Everett Ellin remembers making his case for the digital museum and shared data:
So museums should know how to reduce all records, all registrar records, records of accessions, to a digital file, and each file is kept in an archive, a digital archive, and we tie all the archives together by a computer network. We take all these archives and we link them up, and then when a technology comes that I know is certain that will let you take reasonably good photos digitally, then we will make digital files of those photos and we will put that in a separate part of the same archive - I have that language from 1966 in print - and we will begin to get into the electronic age. And we or you will be ready for the day when you see what I mean about that you are a medium, and that you have to stand toe to toe with mass media, because it's going to be a battle of images inevitably - inevitably. (Kirwin, 2004)
Notes
1. CDWA Lite: Specification for an XML Schema for Contributing Records via the OAI Harvesting Protocol. Available at http://www.getty.edu/research/conducting_research/standards/cdwa/cdwalite.pdf.
2. Cf. http://www.getty.edu/research/conducting_research/standards/cdwa/cdwalite.html.
3. Grant funds were used exclusively to off-set museum costs; to pay an external contractor for the creation of the data extraction tool; to pay an external contractor for a piece of data analysis; and to pay for travel to face-to-face project meetings. OCLC contributions for project management and data analysis were in-kind.
4. Smarty is a templating language — cf. http://www.smarty.net/.
5. MIMSY XG was previously owned by Willoughby, and has been acquired by Selago Design in 2009.
6. Available as Open Source through the OpenSiteSearch project at SourceForge http://opensitesearch.sourceforge.net/.
7. Available at http://www.oclc.org/research/activities/museumdata/methodology.pdf.
8. Of these 131 units of information bearing data content, 67 are data elements, and 64 are attributes. For a detailed view of CDWA Lite information units of information bearing data content, as well as a mapping to CCO, please see http://www.oclc.org/research/activities/museumdata/mapping.xls.
9. There is a slight discrepancy between the schema and the documentation: in the schema, recordID and <recordType> are only required if their wrapper element (recordWrap) is present; the documentation, however, calls both data elements "required."
10. A detailed mapping of CDWA Lite to the COBOAT default mapping can be found in the document "CDWA Light, CCO, COBOAT mapping", available from http://www.oclc.org/research/activities/museumdata/mapping.xls.
11. All quotes in this block refer to: http://www.getty.edu/research/conducting_research/standards/cdwa/cdwalite.pdf.
12. Cf. http://omeka.org/codex/Plugins/OaipmhHarvester.
13. Cf. http://www.getty.edu/research/conducting_research/vocabularies/contribute.html#cona.
14. Cf. http://odai.research.yale.edu/cross-collection-discovery.
15. Cf. http://odai.research.yale.edu/digital-asset-management-program-kickoff.
Bibliography
Chan, Sebastian. OPAC2.0 — OpenCalais meets our museum collection / auto-tagging and semantic parsing of collection data. Fresh + New(er). Powerhouse Museum, March 31, 2008.
Crofts, Nicholas. 2008. Digital assets and digital burdens: obstacles to the dream of universal access. Paper presented at the annual conference of the International Documentation Committee of the International Council of Museums (CIDOC), September 15-18, in Athens, Greece.
Dowden, R., and S. Sayre. 2009. Tear Down the Walls: The Redesign of ArtsConnectEd. In J. Trant and D. Bearman (eds). Museums and the Web 2009: Proceedings. Toronto: Archives & Museum Informatics. Published March 31, 2009.
Elings, M.W. and Günter Waibel. 2007. Metadata for All: Descriptive Standards and Metadata Sharing across Libraries, Archives and Museums. First Monday 12, no. 1.
Ellin, Everett. 1968. An international survey of museum computer activity. Computers and the Humanities 3, no 2: 65-86.
Getty Research Institute. Categories for the Description of Works of Art Lite. J.Paul Getty Trust.
Harpring, Patricia. 2009. Museum Data Exchange: CCO Evaluation Criteria for Scoring.
IBM Federal Systems Division and Everett Ellin. 1969. An Information System for American Museums: a report prepared for the Museum Computer Network. Gaithersburg MD: International Business Machines Corporation. Smithsonian Institution Archives, RU 7432 / Box 19.
Kirwin, Liza. Oral history interview with Everett Ellin, 2004 Apr. 27-28, Archives of American Art. Smithsonian Institution..
Misunas, Marla and Richard Urban. A Brief History of the Museum Computer Network.
Parry, Ross. 2007. Recoding the museum: digital heritage and the technologies of change. Museum meanings. London: Routledge.
Trant, Jennifer. searching museum collections on-line — what do people really do?. jtrant's blog. Archives & Museum Informatics, January 1, 2007.
About the Authors
 |
Günter Waibel is a Program Officer in OCLC Research. He focuses on describing, sharing, aggregating and disseminating cultural materials in a networked environment, as well as the intersection of libraries, archives and museums. Günter served on the Museum Computer Network (MCN) board of directors from 2003 to 2006, and is a past board member of the Association of American Museum's (AAM) Media & Technology Committee. He currently blogs at hangingtogether.org, and tweets as GuWa. Günter teaches as adjunct faculty in the School of Information Studies at Syracuse University, New York, and has been a guest speaker in San Jose State University's Archival Studies program, and John F. Kennedy University's Museum Studies program.
|
 |
Ralph LeVan joined OCLC in 1987 where he led the development of the retrieval software that underlies the FirstSearch service (Newton). He then led the development of OCLC's reference Z39.50 server and Z39.50-to-Web gateway (WEBZ), which became the interface development environment for FirstSearch. More recently, he has produced a second generation of database software (Pears), which is available as Open Source from OCLC Research. He is again looking at database interfaces and is working on the initiative to implement Z39.50 as a Web Service (SRW, also available as Open Source).
|
 |
Bruce Washburn is a Consulting Software Engineer in OCLC Research. He provides software development support for OCLC Research initiatives and participates as a contributing team member on selected research projects. In addition, he provides software development support for selected OCLC Products and Services. At OCLC Washburn has been a part of the product teams that developed and maintain CAMIO, Archive Grid, the WorldCat Search API, and OAIster. For OCLC Research, he is working on the Analyzing Archival Descriptive Practice and Museum Data Exchange projects.
|
|